Gemini 3.1 Pro: Deep thinking is here
By Daniel Ensminger
Daniel Ensminger explains why Google's new thinking_level API and massive 64K token output limit in Gemini 3.1 Pro simplifies AI reasoning.
Tuning the Brain: The Thinking Level API
Google finally killed the thinking_budget parameter, and I couldn't be happier. Trying to guess the exact token allocation required for reasoning was always a shot in the dark. You usually ended up either starving the model mid-thought or wasting compute on trivial tasks.
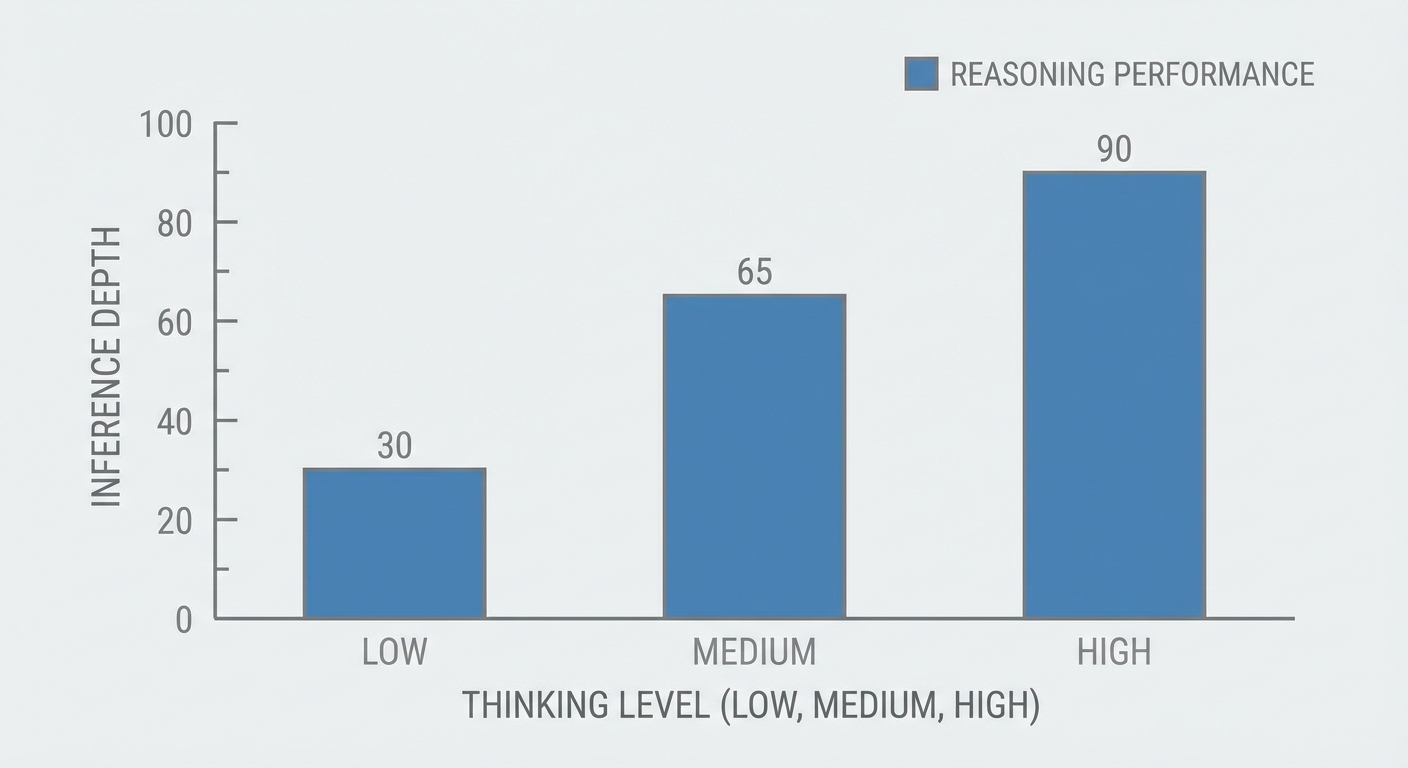
Today, with the Gemini 3.1 Pro rollout, we get the thinking_level parameter. It taps directly into Google's new Three-Tier Thinking System, giving us exactly three deterministic dials: LOW, MEDIUM, and HIGH. This is a massive developer experience improvement. You no longer manage arbitrary integer budgets; you dictate the architectural depth of the inference tree. LOW behaves like a standard forward pass, while HIGH essentially unlocks a full Monte Carlo Tree Search for deep deliberation.
To use it, you need to bump your SDK immediately. If you are on anything older than google-genai version 1.51.0, the API will flat-out reject the request with a validation error.
from google import genai
from google.genai import types
client = genai.Client()
response = client.models.generate_content(
model='gemini-3.1-pro',
contents='Resolve the race condition in this distributed lock implementation...',
config=types.GenerateContentConfig(
thinking_level='HIGH'
)
)Handling the 64K Output Surge
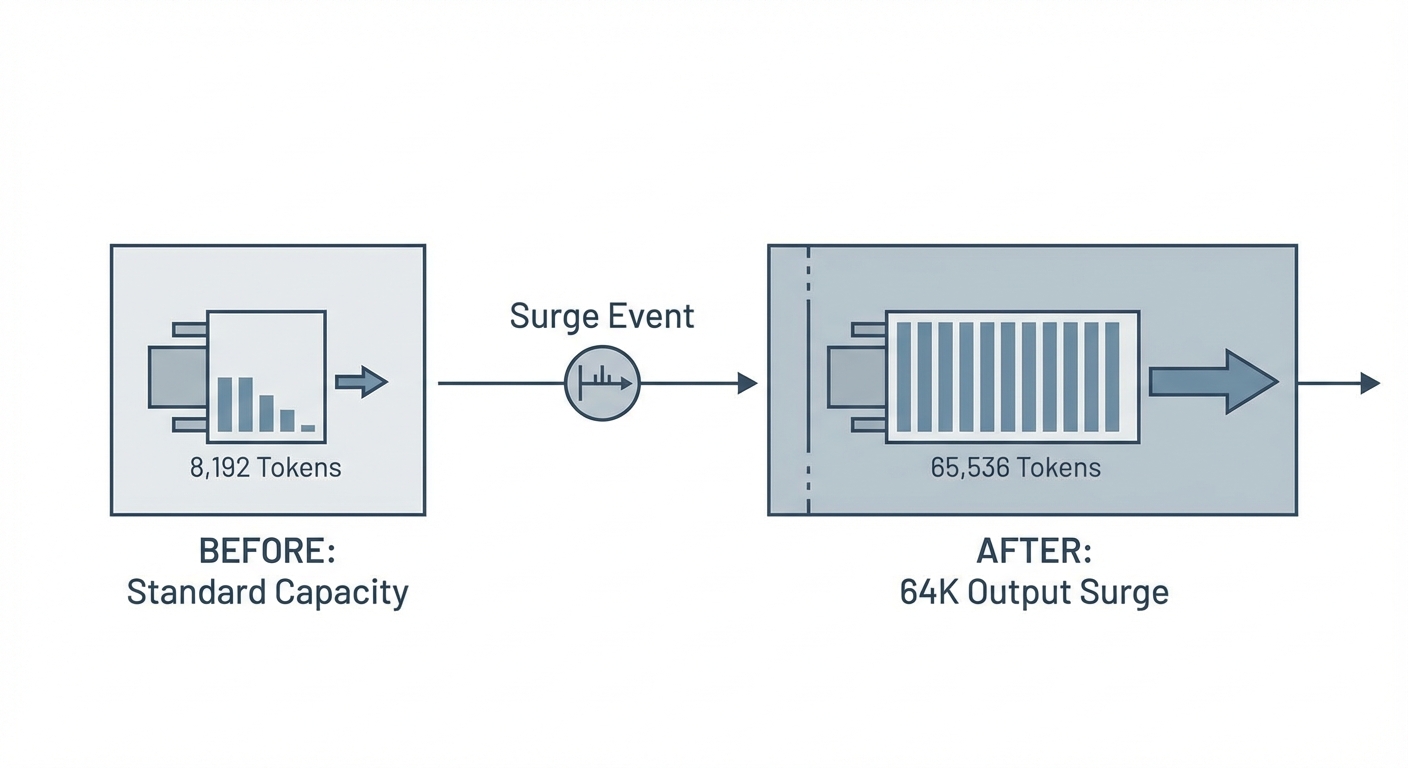
If you were building complex code generators or parsers on 3.0, you probably hit the output truncation wall repeatedly. Gemini 3.1 Pro fixes this by bumping the max output to a massive 65,536 tokens. You can finally spit out monolithic React applications or comprehensive Kubernetes cluster definitions in a single shot.
There is a major gotcha, though. For backward compatibility, the API still enforces an annoying 8k default floor. If you want the full 64K capacity, you must explicitly declare it in your configuration. Do not rely on the implicit defaults, or your payloads will silently truncate right when the logic gets interesting.
This massive output surge pairs perfectly with the new 'Thought Signatures' feature. Previously, if you chained prompts in a lengthy multi-turn session, the model aggressively discarded its internal reasoning scratchpad between turns to save memory. Thought Signatures explicitly persist the hidden reasoning state in the KV cache across turns. When you ask for a bug fix on token 50,000, the model actually remembers why it made a specific architectural choice back at token 2,000.
config = types.GenerateContentConfig(
thinking_level='HIGH',
max_output_tokens=65536,
system_instruction="You are a senior systems engineer.",
# Enable persistence across multi-turn sessions
enable_thought_signatures=True
)
Agentic Performance and Tool-Calling
For high-fidelity agentic workflows, standard text-in/text-out doesn't cut it. If your app relies on strict JSON schemas and external APIs, you need to target the gemini-3.1-pro-preview-customtools endpoint.
Google clearly re-engineered their Mixture-of-Experts (MoE) architecture specifically to handle deterministic formatting. The MoE router now effectively delegates parameter extraction and schema-matching to a dedicated, highly rigid sub-network. The result is that complex tool-calling accuracy is ruthlessly precise. Hallucinated JSON keys or missing required arguments are practically a thing of the past.
But let's talk about the real-world performance trade-offs. Gemini 3.1 Pro absolutely dominates pure logic, multi-step planning, and semantic routing. However, if you are building an autonomous DevOps agent executing raw bash commands against terminal-based infrastructure, GPT-5.3-Codex still holds a noticeable edge. Gemini is the superior software architect, but Codex remains the superior sysadmin when it comes to navigating broken Linux environments.
The Verdict: Reasoning vs. Execution
The benchmark numbers speak for themselves, but seeing them in production is another story. Hitting a record-breaking 77.1% on the ARC-AGI-2 benchmark means we are crossing a serious threshold. Abstract logic isn't just being probabilistically simulated anymore—it's functionally reliable.
Your configuration strategy should be straightforward from today onward. Use the HIGH thinking level when tackling GPQA Diamond-tier problems. It scores an absurd 94.3% on those benchmarks, reliably dismantling PhD-level logic puzzles. However, you will pay for it heavily in latency.
For routine data extraction, API formatting, or basic scaffolding, drop the level to LOW. The Time-To-First-Token (TTFT) on the lowest tier is practically instant, making it perfect for real-time user-facing features where speed beats deep reflection.
This release fundamentally shifts the bottleneck. The limitation is no longer the model's reasoning capacity; it's our ability to write good orchestrators and robust tools. The reasoning engine is finally mature enough to handle whatever we throw at it.
Next steps: Run pip install --upgrade google-genai to get version 1.51.0, update your GenerateContentConfig to uncap that 8k output floor, and start aggressively testing the HIGH thinking level on your oldest, hardest backlog issues.