Sonnet 4.6: My New Daily Driver
By Daniel Ensminger
I’m switching my default model to Sonnet 4.6 after seeing its flagship-level engineering performance at a fraction of the cost.
It’s been about 48 hours since Anthropic dropped the v4.6 lineup, and I’ve spent the last two days aggressively refactoring my agent workflows.
For the past year, the rule of thumb was simple: use Opus for complex reasoning/architecture and Sonnet for speed/codegen. That heuristic is dead.
After running Sonnet 4.6 through my standard gauntlet of repo-wide refactors and automated testing loops, I’m changing my default model ID. Here’s why Sonnet 4.6 is the new daily driver for engineering work, and why Opus is becoming a niche tool for researchers.
Opus Performance on a Budget
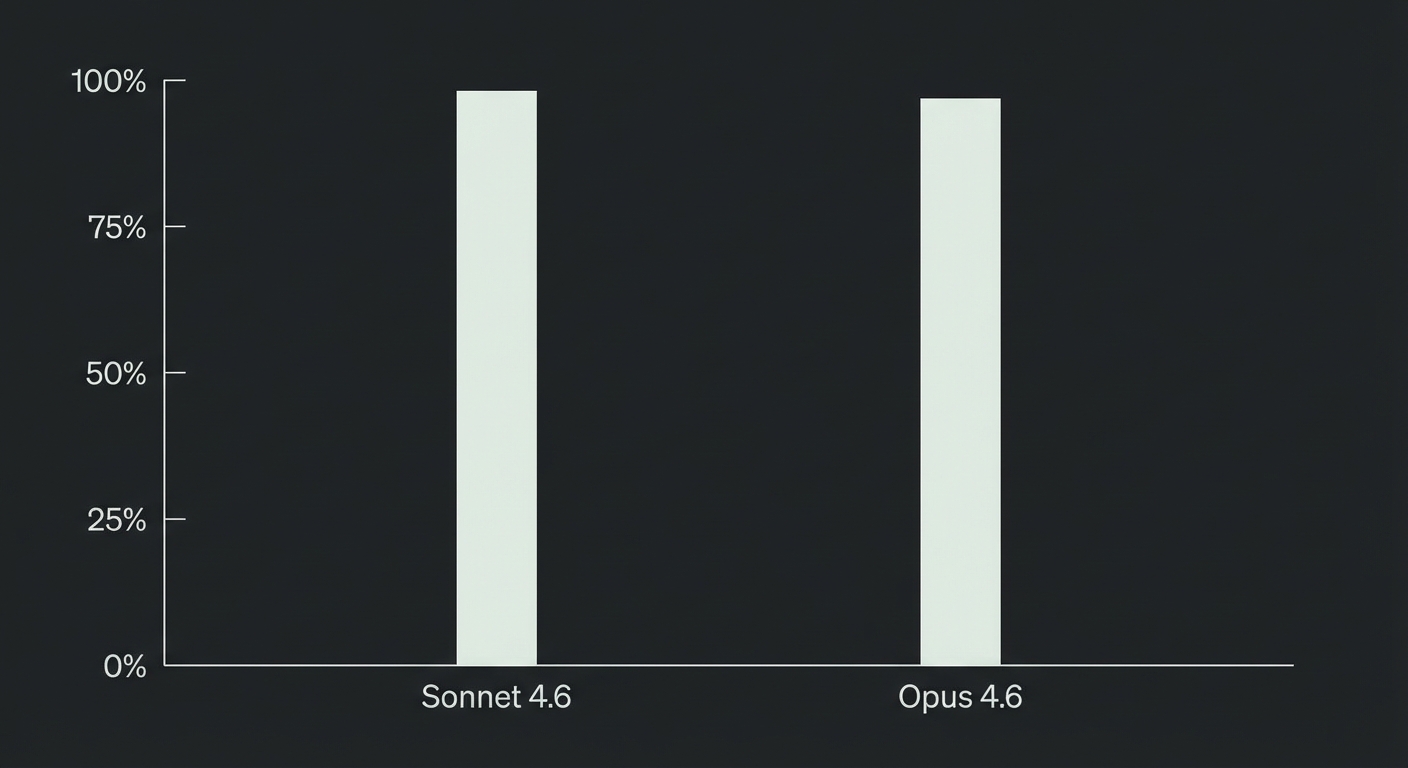
Let’s look at the numbers that actually matter to us. On SWE-bench Verified, Sonnet 4.6 hit 79.6%, statistically tying it with Opus 4.6.
If you’re building in Cursor or running a PR review bot, you know that "intelligence per dollar" is the only metric that scales. Sonnet 4.6 delivers flagship-level engineering performance at roughly 80% lower cost than the new Opus.
I ran a test suite generating integration tests for a legacy Python backend. Sonnet 4.6 didn't just generate the boilerplate; it correctly inferred undocumented edge cases in the payment gateway logic that usually required Opus-level reasoning to catch.
When you can run five inference loops with Sonnet for the price of one Opus call, the math forces your hand. For automated pipelines, iteration speed and retry budgets beat raw single-shot IQ every time.
Adaptive Thinking & 1M Context
The most immediate DX improvement is the new effort parameter. We finally have control over the model's "thinking time" without convoluted prompt engineering.
In the API, it looks like this:
{
"model": "claude-4-6-sonnet-20260219",
"max_tokens": 8192,
"thinking": {
"type": "adaptive",
"effort": "high" // Options: low, medium, high
},
"messages": [...]
}Setting effort: "high" forces the model to generate internal reasoning tokens before outputting the final code. I’ve found this eliminates those frustrating moments where the model hallucinates a library import because it rushed the implementation. It essentially allows you to scale reasoning tokens per request based on the complexity of the ticket.
Then there’s Context Compaction. If you’ve built long-running agents, you know the pain of managing chat history. Sonnet 4.6 handles this natively, summarizing and discarding irrelevant context layers to prevent the dreaded context window overflow crash.
Speaking of windows, the 1-million-token context (beta) is live. I dumped an entire mid-sized Go microservice architecture (docs + code) into a single prompt to ask for a threat model analysis. It ingested the whole thing and pointed out a race condition in the gRPC handler. No RAG required.
Real-World Automation: Computer Use 2.0
Computer Use in late 2024 was a cool party trick that broke if a popup appeared. Version 2.0 is production-ready.
Sonnet 4.6 scores 72.5% on OSWorld-Verified. This isn't just about reading screenshots; it’s about reliable OS-level execution. I set up a script yesterday to log into AWS Console, navigate three layers of poorly designed UI, and grab CloudWatch logs for a specific error pattern.
In previous versions, the model would get confused by the DOM structure or miss a loading spinner. Sonnet 4.6 handles asynchronous UI states with surprising patience. It waits. It verifies.
For those of us building autonomous dev loops (where the agent runs the code, sees the error, and fixes it), this is the missing link. The GUI navigation is optimized for long-running loops, meaning you can actually let it run overnight without waking up to a confused agent stuck on a "Session Expired" modal.
The Fine Print: Sonnet vs. Opus
Before you cancel your Opus tier API keys, let’s talk about the trade-offs.
1. Pricing: Sonnet 4.6 is locked at $3.00/1M input and $15.00/1M output. While cheap compared to Opus, remember that Adaptive Thinking increases your token count. If you run everything on effort: "high", you are generating significantly more output tokens (reasoning traces). Budget accordingly.
2. The "Einstein" Gap: Opus 4.6 still holds a lead in GPQA Diamond (PhD-level science questions)—about 17 points higher than Sonnet. If you are working on novel cryptographic proofs, heavy mathematical modeling, or biological research, Opus is still the king. Sonnet is an engineer; Opus is a scientist.
3. Latency: With effort: "high", Sonnet feels slower than 3.5 Sonnet. It’s thinking. If you need sub-second chat responses for a CLI tool, keep the effort parameter on low or stick to Haiku.
The Verdict
For 95% of software engineering tasks—debugging, refactoring, writing tests, and navigating cloud consoles—Sonnet 4.6 is now the optimal choice. It hits the diminishing returns curve of intelligence perfectly.
I’ve updated my .env files. You should probably update yours too.