Why I'm refactoring for Opus 4.6
Claude Opus 4.6 just dropped with a 1-million token context window and adaptive thinking, forcing a total rethink of how I build production AI agents.
Anthropic dropped Claude Opus 4.6, and I’ve already torn apart half my production code.
Usually, a model update is a simple string swap in an environment variable. Not this time. Opus 4.6 isn't just "smarter"; it fundamentally changes how we handle state, context, and output limits. The introduction of native Agent Teams and the shift in how the model handles "thinking" has broken my favorite JSON-forcing hacks—but the trade-off is worth it.
Here is what I’m changing and why.
Massive Context and Giant Outputs
The headline feature is the 1-Million Token Context Window (currently in Beta), but the real story is retrieval accuracy. We’ve had 1M+ context in other models for a while, but they usually fall apart when you ask them to find a specific needle in a haystack of documentation.
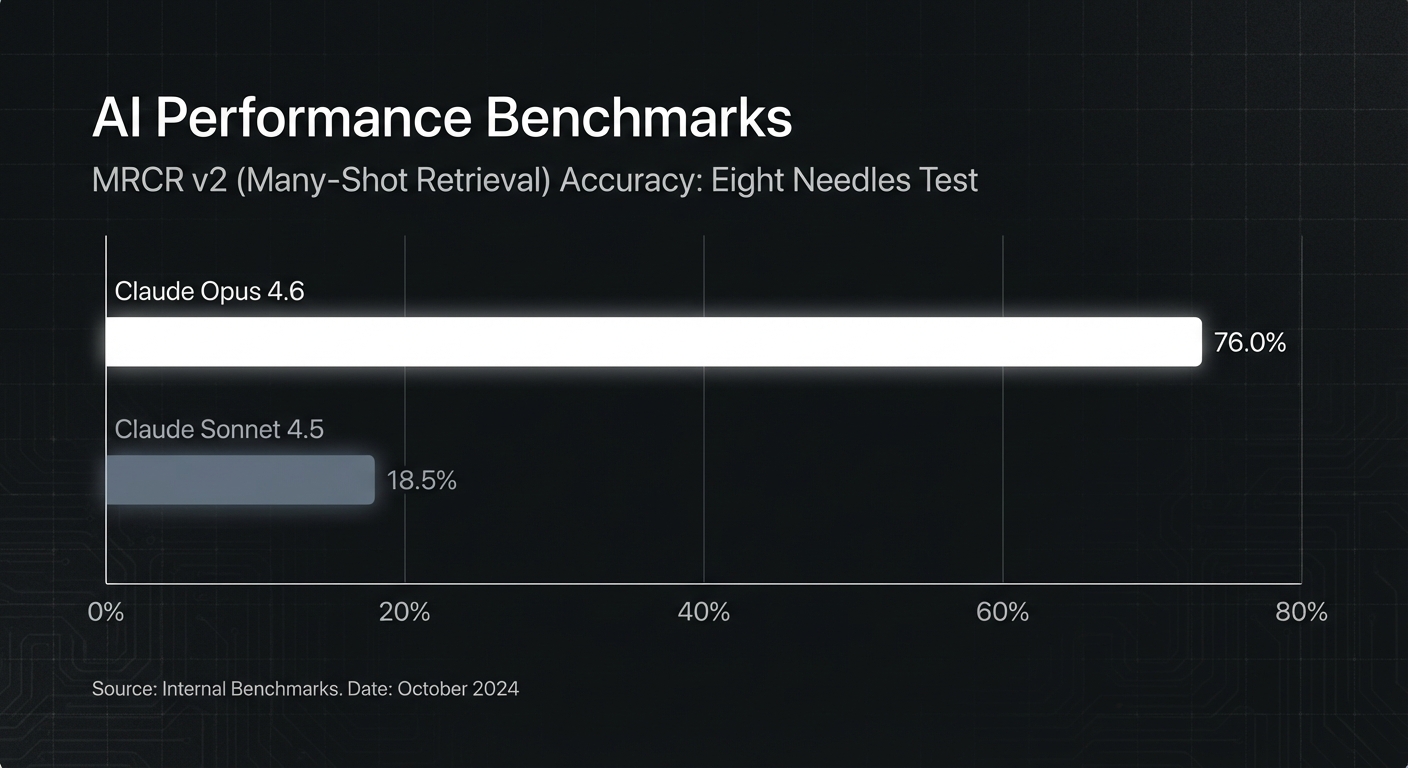
On the MRCR v2 (Many-Shot Retrieval) benchmark, Opus 4.6 hits 76% accuracy on the "eight needles" test. For comparison, Sonnet 4.5 scored 18.5%. That is the difference between a demo and a production-ready legal analysis tool. I’m currently testing ingesting entire repositories rather than relying on RAG chunking, and the "context rot"—where instruction following degrades as context grows—is barely noticeable.
More importantly for my workflow, the output limit has doubled to 128,000 tokens.
Previously, asking Opus to refactor a large module meant pagination logic or getting cut off mid-function. Now, I can generate full software modules in a single shot. The catch? You have to stream. If you try to wait for a standard HTTP response on a 128k generation, you will hit timeout limits before the model finishes writing. I’m rewriting all my generation handlers to enforce streaming for long-form tasks.
Moving to Adaptive Thinking
This is the breaking change that hurts the most right now, but it solves the biggest inefficiency in my billing.
In Opus 4.5, we had to guess the budget_tokens. If I allocated 16k tokens for thinking and the problem was simple, I wasted money and latency. If I allocated too little, the reasoning failed.
Opus 4.6 deprecates manual budgets for Adaptive Thinking. We now control the propensity to think via an effort parameter.
# Old Way (Deprecated)
thinking = {"type": "enabled", "budget_tokens": 16000}
# New Way
thinking = {
"type": "adaptive"
}
output_config = {
"effort": "max" # options: low, medium, high, max
}I’m defaulting to medium for general tasks and max strictly for root cause analysis and security audits.
The Breaking Change: This kills Assistant Message Prefilling. If you’re like me, you used to force JSON output by prefilling the assistant's message with {. Because Opus 4.6 now generates "Thinking Blocks" before the final response, prefilling the response body causes a collision. I’m having to rip out every instance of prefill-forcing and rely strictly on schema definitions.
Infinite Loops with Context Compaction
If you run long-lived agents, you have a function somewhere in your codebase called summarize_history() that runs every 10 turns to save tokens.
I am deleting that function today.
Opus 4.6 introduces Context Compaction. It’s a server-side mechanism where the model automatically identifies "rotten" context—information that is no longer relevant to the immediate goal—and summarizes it into a compressed state representation.
# Enabling compaction
client.messages.create(
model="claude-opus-4-6",
messages=history,
context_compaction="auto" # The magic setting
)This effectively enables infinite loops for agentic persistence. I no longer have to manage the sliding window on the client side. The API simply hands back a compacted history ID when the threshold is hit.
Migration and Safety Specs
Beyond the code, there are deployment realities. The model ID is claude-opus-4-6, and it is available now on the Anthropic API, AWS Bedrock, and Google Vertex AI.
A note on safety: This model is rated ASL-3 (AI Safety Level 3). Anthropic has tightened the guardrails specifically around software engineering tasks that look like sabotage or unauthorized access. If your agent does security testing or penetration testing, you might hit refusals that didn't exist in 4.5. You need to adjust your system prompts to clearly define the authorized scope of the work.
The Verdict
I’m spending the weekend refactoring not because I want to, but because the code I’m deleting—manual context window management, token budgeting, and output stitching—is code I never wanted to write in the first place.
The API is cleaner, even if the migration is a pain. If you rely on prefilling for structured output, start fixing that now. The 128k output limit is waiting.